Subvaloración en la importación de celulares en Colombia: caracterización a partir de series temporales e inteligencia de negocios
Undervaluation of Cell phone’s Colombia imports: characterization from time series and business intelligence
Revista PERSPECTIVAS
EN INTELIGENCIA
María Carolina Velasco Peña1* y Vladimir Osorio Isaza2
(1) Escuela de Inteligencia y Contrainteligencia “BG. Ricardo Charry Solano”, Bogotá, D. C. – Colombia, mvelascop@dian.gov.co
(2) Escuela de Inteligencia y Contrainteligencia “BG. Ricardo Charry Solano”, Bogotá, D. C. – Colombia, vsaza35@gmail.com
* Autor a quien se dirige la correspondencia
Volumen 14, Número 23, Enero - Diciembre 2022, pp. 33-61
ISSN 2145-194X (impreso), 2745-1690 (en línea)
Bogotá D.C., Colombia
http://doi.org/10.47961/2145194X.332
Fecha de recepción: 17/07/2022 | Fecha de aprobación: 26/10/2022
Resumen
El mercado de celulares en la república de Colombia es objeto de cuestionamientos por subvaloración y las tasas y formas de hurto en las que los victimarios generan lesiones y homicidios a las víctimas. Es menester de la Inteligencia Estratégica analizar holística y científicamente todas las variables y categorías constitutivas de un fenómeno o una realidad. Para el caso de los celulares, uno de los elementos a estudiar es todo el proceso de importación al Territorio Aduanero Nacional (TAN) de estos dispositivos. Este artículo de investigación se enfoca primero en determinar el comportamiento de las variables Tasa de Cambio y Precio FOB, utilizando series temporales VAR. Luego, se analizan de forma relacional las variables de importación para caracterizar conductas aduaneras al momento de hacer los procesos de nacionalización de los celulares. Las variables relevantes para este análisis relacional son: año de presentación, ciudad y país exportador, país de procedencia, país de origen, fecha de aceptación y de compra; fecha de levante, selectividad, tipo de declaración y fecha de declaración anterior. Como resultados relevantes se tiene evidencia de relación indirecta entre la Tasa de Cambio y el Precio FOB, lo que puede configurar contrabando técnico o subvaloración; se presenta un fenómeno de no variación del precio FOB en los años 2015 a 2020 y, por último, se muestra cómo también hay subvaloración legal amparada por el Artículo 175 de la Ley 1819 de 2016.
Clasificación JEL: C22, E62, F52, P45
Palabras clave: VAR; modelo predictivo; mercado celular Colombia; inteligencia de negocios; subvaloración.
Abstract
The cell phone market in the Republic of Colombia is subject to questioning due to undervaluation, the rates and forms of theft, in which the perpetrators generate injuries and homicides to the victims. Is necessary for Strategic Intelligence to analyze holistically and scientifically all the variables and constitutive categories of a phenomenon or reality. In the case of cell phones, one of the elements to study is the entire process of importing these devices into the National Customs Territory (TAN). This research article first determines the behavior of the Exchange Rate and FOB Price variables using VAR time series. Then, the import variables are analyzed in a relational way to characterize customs behaviors at the time of carrying out the cell phone nationalization processes. The relevant variables for this relational analysis are year of presentation, exporting city and country, country of origin, country of origin and purchase, release date, selectivity, type of declaration and previous declaration date. As relevant results, there is evidence of an indirect relationship between the Exchange Rate and the FOB Price, which can configure technical contraband or undervaluation; there is a phenomenon of non-variation of the FOB price in the last 10 years; and finally, it is shown how there is also legal undervaluation protected by article 175 of Law 1819 of 2016.
Keywords: VAR Series; Predictive model; mobile market Colombia; Business Intelligence; undervaluation.
Introducción
La producción de Inteligencia Estratégica debe comprobar o descartar afirmaciones basadas en juicios de valor de expertos y que se dan por “ciertas o verdaderas”. Este es el caso del mercado de celulares y el presunto detrimento al fisco nacional por contrabando técnico o incentivos legales de estos equipos electrónicos que son importados al Territorio Aduanero Nacional colombiano. De estos equipos se asume que van al mercado legal, pero no se puede descartar que algunos teléfonos pueden ser usados por el crimen transnacional para financiar actividades legales e ilegales. Independientemente del comercializador, y de lo que se financie, el contrabando técnico y/o los incentivos legales causan deterioro al fisco nacional (Estadística delictiva, 2017). Los expertos tienden a sustentar que la tasa de cambio y sus variaciones afectan el valor FOB que se declara o las cantidades que se nacionalizan.
Se dan hechos asociados a la subvaluación y el contrabando como los hechos tipificados en diarios de circulación nacional “Celulares de menos de Usd 5 entran legales al país” (Tiempo, 2015b); “caen las ventas de celulares en Colombia, hasta un 40% del mercado de teléfonos móviles Enel país sería de contrabando” (Tiempo, 2015a); y “Policía incauta 40 iPhone 12 de contrabando en el aeropuerto Eldorado” (BLU Radio, 2020).
En este trabajo de investigación se utilizan elementos de la cuarta revolución industrial, como son la analítica y la ciencia de datos (Joyanes Aguilar, 2017), para explicar y probar si existe o no un fenómeno que involucra contrabando técnico o incentivos legales que van en detrimento del fisco nacional. De la analítica de datos se usan la descriptiva y predictiva, no se utiliza la analítica de diagnóstico ni la prescriptiva. Los datos son extraídos de la página oficial de la DIAN hasta el año 2020, fecha en la que ya no estuvieron disponibles al público (Dirección de Impuestos y Aduanas Nacionales - DIAN, s. f.). Por las políticas de “Habeas Data” la institución de aduanas protegió los datos de los formularios 500 (formularios de importación), hecho que, de acuerdo con el artículo “China, Estados Unidos y 5G: Capitalismo de Vigilancia, Geopolítica y Geoestrategia” es relevante, pues “la tecnología inteligente […] recopila una cantidad de datos sin precedentes; a esto es lo que se denomina Big Data o macrodatos. Esta cantidad de datos son los que pueden usarse para hacer perfilamiento comercial o político” (Osorio I. et al., 2021).
Para realizar la ETL (Extract, Transform and Load) se utiliza Excel y Power Query, para el análisis, Power BI y paquetes estadísticos de R.; las variables base son la Tasa de Cambio y el valor FOB[1] de las mercancías. La tasa de cambio utilizada en las aduanas es diferente de la Tasa Representativa del Mercado o TRM (Banco de la República, s. f.). La tasa de cambio con la que se calculan las operaciones aduaneras en una semana cualquiera, es la última TRM de la semana inmediatamente anterior, y es parte de un dato objetivo y cuantificable (DIAN, Ministerio de Hacienda y Crédito Público, 2022). El valor FOB en Colombia siempre se da en dólares de Norteamérica (USD). Con las series de tiempo se pueden corroborar o descartar afirmaciones referidas a la relación entre Valor FOB y Tasa de Cambio. Se hará el análisis con modelo VAR[2] a una base de datos de importación en la que solo se pierden cuatro (4) vectores o registros de datos de un total de 95.895.
Las variables relevantes utilizadas en las descripciones y análisis para este análisis relacional son: año de presentación, ciudad y país exportador, país de procedencia, país de origen y de compra, cantidad de unidades físicas; valor FOB, valor de ajuste FOB, arancel, UVT, fecha de levante, selectividad, tipo de declaración y fecha de declaración anterior. Las variables definidas operacionalmente son formulario 500, SYGA y control simultáneo. El primero es el documento prescrito y exigido por la DIAN para ser utilizado en la declaración del Régimen de Importación. Es el formulario que acredita la introducción legal de una mercancía al territorio aduanero nacional y funge para este trabajo como el instrumento para recolección de datos. El segundo es el Sistema de Información y Gestión Aduanera. El tercero y último es la acción ejercida por los funcionarios aduaneros desde el momento de la presentación de la declaración aduanera y hasta el momento en que se nacionalicen las mercancías (Dirección de Impuestos y Aduanas Nacionales - DIAN, s. f.).
Marco Teórico
Analítica y Ciencia de Datos
La analítica de datos es definida por Luis Joyanes Aguilar como aquellos procesos y actividades donde se obtienen y evalúan datos para identificar riesgos, fraudes y errores; se examinan datos en bruto y se inferencia respecto del contenido de estos. Especifica Joyanes que la analítica descriptiva prepara y analiza datos históricos con los que se identifican patrones y tendencias; utiliza esos datos para explicar lo que sucedió en el pasado. A su vez, la analítica predictiva descubre o determina patrones ocultos en los datos, aplicando matemáticas y estadística para determinar relaciones asociadas a eventos futuros, respondiendo a la pregunta ¿qué va a pasar? (Joyanes Aguilar, 2017, pp. 319 - 321). Por otra parte, la ciencia de datos comprende áreas como la investigación tradicional, las matemáticas, estadísticas, informática, computación y el conocimiento o dominio del entorno (Joyanes Aguilar, 2017, pp. 390 - 391). El entorno de este trabajo de investigación es el comercio exterior colombiano y la operación aduanera sobre la subpartida 8517.12.00.00 (Celulares).
Fraude Aduanero
Respecto del fraude aduanero, dentro de los actos del comercio internacional que se derivan del intercambio de bienes y servicios, surgen actividades ilícitas y prácticas fraudulentas. Un tema asociado a estas malas prácticas es el fraude comercial aduanero, considerado como todo acto por el cual un particular u organización trata de engañar a la autoridad aduanera y, en consecuencia, corrompe procesos, falsea o adultera información o documentación con el propósito de introducir mercancías a un valor inferior, a fin de evadir el pago de los derechos e impuestos que corresponden a los actos de importaciones o exportaciones, o para eludir la aplicación de prohibiciones o restricciones previstas normativamente (Paravicini Guzmán, 2016).
Debido a esto, los efectos del fraude comercial aduanero representan un impacto negativo sobre la economía de un país, por ello, en su estudio del entorno internacional, la Organización Mundial de Aduanas advierte que las administraciones aduaneras en todo el mundo se enfrentan a retos impredecibles, lo que requerirá de procesos de control eficaces y ágiles (Secretaría General de la Comunidad Andina, 2007). En este sentido, el entendimiento situacional y la toma de decisiones asertivas por parte de los líderes de los Estados y sus instituciones se vuelven relevantes en el campo específico de su gestión para la planeación y el cumplimiento de los objetivos estratégicos (Castro et al., 2020). Es allí donde la inteligencia estratégica, concebida como proceso, se convierte en una herramienta útil que permite analizar, evaluar, enfrentar y anticipar amenazas, a fin de salvaguardar los intereses del Estado.
El Fraude aduanero en Colombia
En Colombia el fraude aduanero tiene dos dimensiones, una administrativa, en tanto se produce en el proceso de legalización de una operación comercial, y una penal, en la medida en que se demuestre que constituye un acto delictivo doloso de defraudación fiscal. Tanto uno como otro se pueden configurar de diferentes maneras, y se describen en el texto “La Lucha contra el Fraude” (Secretaría General de la Comunidad Andina, 2007). Sin embargo, esta investigación se centra en la subvaluación, que se configura cuando en los procesos de importación se falsea o altera el valor de las mercancías en las facturas comerciales, buscando reducir la base impositiva para lograr una liquidación menor, además de incentivos legales que también coadyuvan a la “subvaluación”.
Taxativamente, el Fraude aduanero está tipificado en el Artículo 8 de la Ley 1762 de 2015, en el que el interés se centra por ilicitud técnica en el proceso de destinación aduanera, donde “hay una intención de infringir un hecho dañoso y de evadir el control del Estado en materia tributaria”. A criterio de Solano y Lombana (Solano M. & Lombana S., 2015), el afán Estatal por prevenir y controlar los delitos de evasión aduanera con base en tecnicismos hace que se adopten medidas legales rigurosas para no mostrarse permisivo frente a este delito. Sin embargo, advierten que la forma para desestimular y prevenir este tipo de prácticas no debe ser a través de la expedición de normas penales, pues una forma más eficiente se puede lograr mediante el fortalecimiento de los controles administrativos.
El Sistema de Gestión del Riesgo Aduanero
En Colombia, la Dirección de Impuestos y Aduanas Nacionales (DIAN), en cabeza de quien reposa la gestión y el control aduanero del país, se encuentra frente al reto de fortalecer su capacidad institucional y realizar una transformación tecnológica. Es por ello que el Gobierno nacional, con la expedición de los decretos 390 de 2016 y posteriormente 1165 de 2019, introdujo en la regulación aduanera el Sistema de Gestión del Riesgo (Meisel Lanner, 2020), con el fin de ser eficiente frente a las amenazas potenciales para prevenir o combatir el uso del comercio para fines que atenten contra la seguridad nacional o las disposiciones de carácter aduanero. Estas actividades se encaminan a la aplicación sistemática de técnicas y procedimientos administrativos que proporcionen a la autoridad aduanera información relevante para detectar un riesgo en el ingreso o salida de mercancías.
En concordancia con este sistema, el Artículo 584 del Decreto 1165 de 2019 (Secretaría del Senado, 2019) ha identificado un riesgo asociado con “la evasión del pago de los tributos aduaneros por distorsión de los elementos del valor en aduana de las mercancías importadas”. Esto, fundamentado entre otros por el Informe de la estimación de la distorsión en el valor de las importaciones colombianas, publicado anualmente por la DIAN. Estos informes muestran en el apartado de estimación del fenómeno de contrabando técnico por subfacturación, que el Capítulo 85 del arancel “Aparatos y material eléctrico, de grabación o imagen” es de los más sobresalientes para este fenómeno; por lo cual, se podría considerar como productos sensibles a los clasificados en este Capítulo, siendo el caso de los “Teléfonos móviles (celulares)” bajo la subpartida arancelaria 8517.12.00.00.
A partir del año 2017, para la importación de teléfonos móviles inteligentes y teléfonos móviles celulares se establecieron como tributos aduaneros un gravamen arancelario de cero por ciento (0%) y una tarifa diferencial del IVA del 19%, con exclusión de esta, siempre y cuando su valor no exceda de veintidós (22) UVT, conforme con el numeral 6 del Artículo 424 del Estatuto Tributario, modificado por el Artículo 175 de la Ley 1819 de 2016 (Secretaría del Senado, 2016b); además de lo previsto en el Inciso segundo del Artículo 1.3.1.12.10 del Decreto 1625 de 2016 (Secretaría del Senado, 2016a), donde precisa que para el cálculo de las UVT se tendrá en cuenta el valor de los dispositivos móviles inteligentes establecidos en la factura o documento soporte de la declaración de importación.
Series de Tiempo
Una serie de tiempo es una serie de observaciones (𝑥ₜ) que se hicieron en un periodo de tiempo; estadísticamente se diferencian en la dependencia de las observaciones para obtener previsiones de futuras observaciones (Subba Rao, 2022, p. 12). Este trabajo de investigación tendrá en cuenta observaciones con puntos fijos equidistantes y periodicidad estable:
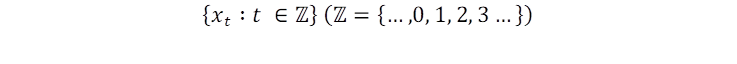
FIGURA 1. Representación gráfica de una serie de tiempo
Fuente: (Lind et al., 2015; Pinzón, 2011)
Gráficamente, en el eje “x” se situará el tiempo, mientras que en el eje “y” se ubicarán los valores de la serie. Para este artículo las observaciones son diarias durante el período comprendido entre los años 2015 a 2020. Por tratarse de un trabajo en el que se aplica analítica de datos, se harán conceptualizaciones básicas de las series de tiempo, y se centra en la aplicación de paquetes estadísticos bajo ambiente R y su interfaz RStudio. Una típica serie de tiempo obedece a la ecuación: Yₜ = μₜ + ϵₜ, esta ecuación relaciona las observaciones, donde μₜ es la media subyacente y ϵₜ son los errores residuales. Yₜ como cualquier otro dato en estadística que se quiera resaltar y normalizar, debe ser transformado linealmente[3]; para series de tiempo esta transformación obedece a:
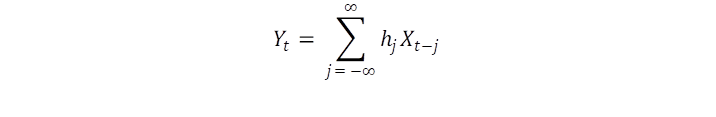
Donde hⱼ son los pesos o valores de las variables independientes y de control. Los paquetes TSeries y Vars se asumen con tendencia paramétrica; se conocen al menos un número finitos de parámetros, como es el caso de las variables conceptuales de las importaciones que llegan al territorio aduanero nacional y sus variables operacionales. En series de tiempo los modelos lineales paramétricos comunes son Y = β₀ + β₁t + ϵₜ o Y = β₀ + β₁t + β₂t² + ϵₜ (Subba Rao, 2022, pp. 15 -19). β₁ y β₂ son desconocidos y son esos valores o pesos que se hallaran a partir del análisis de los datos aduaneros con los paquetes para análisis temporales.
Los componentes de una serie de tiempo, y que serán objeto de análisis en este artículo, son tendencia, estacionalidad y término aleatorio o de error.
FIGURA 2. Componentes de una serie de tiempo.
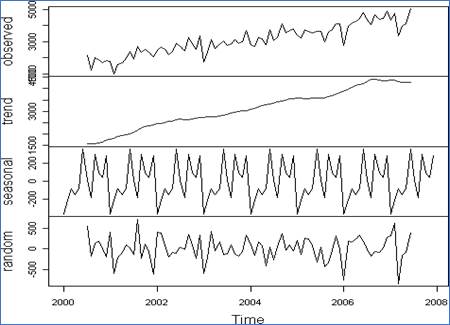
Fuente: (Pinzón, 2011; Time series analysis with applications in R, 2008)
La tendencia son los cambios de largo plazo de la media. La estacional son comportamientos con cierta periodicidad; son valores que se pueden identificar rápidamente y ser eliminados de la serie de observaciones mediante desestacionalización. Por último, el término aleatorio o de error no tiene un patrón como los dos anteriores, es simplemente el resultado de factores que inciden en la serie temporal. Las series de tiempo se clasifican en no estacionarias y estacionarias. Una serie no estacionaria tiene tendencias y/o alta dispersión a lo largo del tiempo, la serie gráficamente no se mantiene alrededor de la media como una estacionaria. Una serie se considera estacionaria cuando es estable a lo largo del tiempo, los valores de la serie se mantienen alrededor de un valor medio y la dispersión es constante a lo largo del tiempo.
FIGURA 3. Clasificación de las series de tiempo.
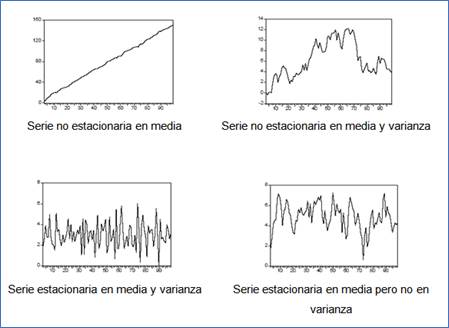
Fuente: (Pinzón, 2011; Time series analysis with applications in R, 2008)
Finalmente, el concepto de raíz unitaria se tendrá en cuenta para la modelación de la serie de tiempo. La raíz unitaria es una tendencia estocástica en la serie temporal. Si la serie tiene una raíz unitaria, esta presenta un patrón sistemático que es impredecible, luego una serie temporal es estacionaria si un cambio en el tiempo no cambia la forma de la distribución; y las raíces unitarias son una causa de no estacionariedad. Las pruebas clásicas para determinar la existencia o no de raíces unitarias son:
H₀: La serie tiene raíz Unitaria, o su equivalente.
H₀: La serie NO es estacionaria.
H₀: La serie NO tiene raíz Unitaria, o su equivalente.
H₀: La serie es estacionaria.
Cuando la serie tiene raíz unitaria, entonces:
FIGURA 4. Prueba de raíz unitaria.
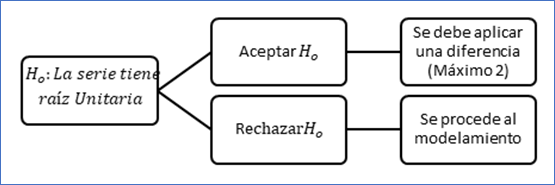
Fuente: (Pinzón, 2011; Time series analysis with applications in R, 2008)
Metodología
Estudio cuantitativo con diseño no experimental, transeccional correlacional o causal (Sampieri, 2018, pp. 178 - 180). Los datos fueron extraídos desde la página oficial de la DIAN en Colombia, en el año 2020. La transformación se realizó utilizando software licenciado Excel y su aplicación Power Query. Las bases de datos que estaban en el web site de la Dirección de Impuestos y Aduana Nacionales tienen como atributo cada uno de los campos del formulario 500 (Declaración de Importación). Los archivos estaban en Excel y contenían la información de todas las importaciones y todas las subpartidas hechas por mes.
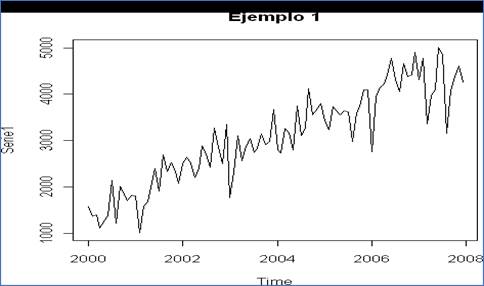
En total se transformaron 13.124.600 datos (137 atributos x 95.895 vectores); al final solo se utilizarían tres atributos para la modelación con las series de tiempo (287.685 datos para estadística predictiva), y 32 atributos (3.068.640 datos) para realizar analítica descriptiva utilizando Power BI. Una serie de tiempo consta de cuatro componentes: 1) Tendencia, 2) variación cíclica, 3) variación estacional, y 4) variación irregular (Lind et al., 2015, p. 568). Las fases de una serie temporal se componen de identificación, estimación, chequeo y predicción. Las fases para el modelamiento son la selección de los datos, representación gráfica, transformación previa de la serie, eliminación de la tendencia, identificación del modelo, estimación de los coeficientes del modelo, contraste de validez del modelo, análisis detallado de los errores y pronóstico (Pinzón, 2011).
FIGURA 5. Flujograma de la metodología de las series temporales.
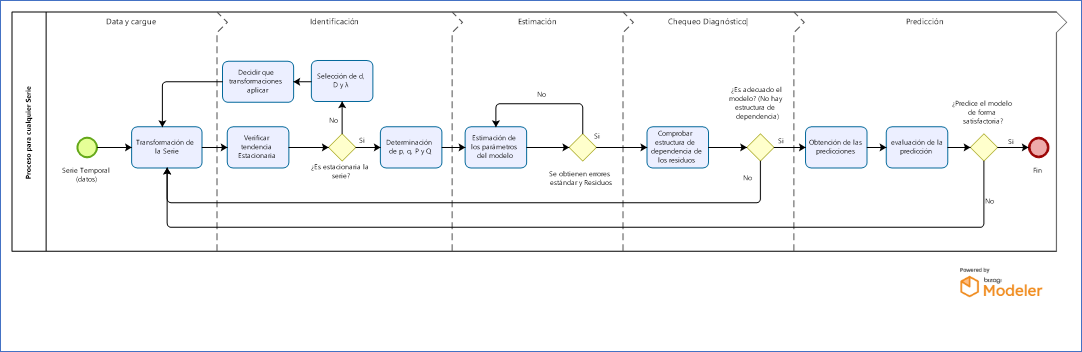
Fuente: Elaboración propia a partir de (Pinzón, 2011), utilizando Bizagi Modeler (https://www.bizagi.com/es/plataforma/modeler)
Resultados
Analítica Predictiva
La base de datos a trabajar registra las importaciones de celulares hechas en Colombia entre los años 2015 a 2020. La base cuenta con 95.895 vectores o registros, de los cuales cuatro (4) no tienen fecha y fueron eliminados. El total de vectores a trabajar será entonces de 95.891. El conjunto de datos tiene tres (3) variables, a saber: Fecha Aceptación, Tasa de Cambio y Valor FOB, esta última expresada en dólares de los Estados Unidos de Norteamérica (USD).
La estructura de este conjunto de datos es:
str(impo_celulares)
## tibble [95,891 × 3] (S3: tbl_df/tbl/data.frame)
##$ Fecha Aceptación: POSIXct[1:95891], format: "2015-01-06" "2015-01-08" ...
##$ Tasa_de_Cambio: num [1:95891] 2392 2392 2392 2405 2392 ...
##$ Valor_FOB : num [1:95891] 250 114548 233776 154670 75246 ...
La variable “Fecha Aceptación”, que está en string (str), no tendrá tratamiento alguno al momento de aplicar “tseries”; solo es la variable que certifica que existe una “secuencia de datos o información, medida en diversos periodos del tiempo, manteniendo un orden cronológico y manteniendo una distancia uniforme, permitiendo que los datos tengan una estructura de dependencia a través del tiempo”.
Dado que las variables Valor_FOB y Tasa_de_Cambio están en escalas diferentes, se aplica la transformación logaritmo natural, eliminando la variable “Fecha aceptación”. Esta variable tiene estructura de tiempo diaria, lo que implica que la relación se buscará en días al momento de aplicar “predict(…… n.ahead = 5, ci = 0.95)”.
Base <- log(impo_celulares[,-1])
Ahora se convierte esta “Base” en una serie de tiempo.
serie <- ts(Base)
FIGURA 6. Gráfico de línea para revisión de tendencias y orden de integración (estacionariedad) con 95.891 vectores.
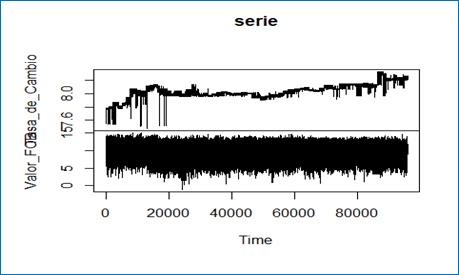
Fuente: Paquete “tseries” de R a partir de (DIAN, 2022).
El objetivo de esta representación gráfica es identificar tendencias y decidir sobre estacionariedad. La FIGURA 6 muestra 95.891 datos que no permiten visualizar ni tendencias ni estacionariedad por periodos de tiempo anuales. La serie Tasa de Cambio pareciera no tener estacionariedad ni en media ni en varianza, tomados todos los años; la serie valor FOB sí pareciera tener estacionariedad en media y varianza, pero es muy difícil conceptuar con certeza al respecto. De hecho, las relaciones que existieron hace siete años en poco pueden aportar al pronóstico actual, por lo que se decide tomar las últimas 120 observaciones del año 2020 (último año disponible).
Base <- log(impo_celulares[95771:95891,-1])
## # A tibble: 6 × 2
## Tasa_de_Cambio Valor_FOB
##<dbl> <dbl>
## 1 8.25 11.2
## 2 8.205.54
## 3 8.20 11.5
## 4 8.20 12.0
## 5 8.20 11.5
## 6 8.25 10.7
Se verifica que la estructura de “Base” quede con las 120 observaciones
str(Base)
## tibble [121 × 2] (S3: tbl_df/tbl/data.frame)
##$ Tasa_de_Cambio: num [1:121] 8.25 8.2 8.2 8.2 8.2 ...
##$ Valor_FOB : num [1:121] 11.2 5.54 11.49 12.05 11.48 ...
FIGURA 7. Gráfico de línea para revisión de tendencias y orden de integración (estacionariedad) con 120 vectores.
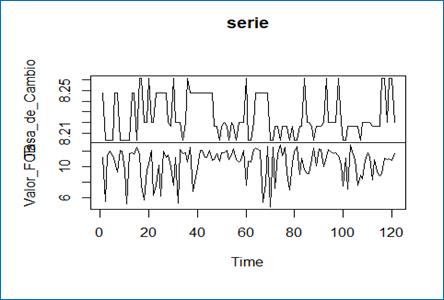
Fuente: Paquete “tseries” de R a partir de (DIAN, 2022).
En esta FIGURA 7, la variable “Tasa de Cambio” podría acercarse más a estacionariedad en media que la variable FOB. Ninguna de las dos tiene estacionariedad en varianza. Si se trata de buscar visualmente algún tipo de relación (Inversa, Directa o No se evidencia), se podría decir que hay una relación inversa entre “Tasa_de_Cambio” y “Valor_FOB”, no es una relación inversamente proporcional, solo es inversa. A lo largo de la gráfica existen periodos en los que, cuando Tasa_de_Cambio” sube, “Valor _FOB” baja; y viceversa, cuando “Tasa_de_Cambio” baja, “Valor_FOB” sube. Esto es apreciación gráfica (que es la primera fase de modelos en series de tiempo), pero se debe demostrar qué tipo de relación hay a partir de los datos. El modelo debe identificar qué relación hay. Los modelos VAR son para verificar relaciones de corto plazo.
Se inicia con la prueba de raíz unitaria. Se sigue utilizando el paquete “tseries” de R (Cran.r-project, 2022; Pinzón, 2011). Se crean variables individuales para poder determinar el grado de integración de cada una de ellas. Los grados de integración que se aceptan son:
· Si una serie es estacionaria, se llama I(0) integrada de orden 0 o grado de integración 0.
· Si no es estacionaria y se debe aplicar una diferencia, se llamará I(1), integrada de orden 1 o grado de integración 1.
· Si no es estacionaria y se deben aplicar dos diferencias, se llamará I(2), integrada de orden 2 o grado de integración 2.
En la creación de las variables individuales se debe tener en cuenta que cuando se hace el cargue inicial del conjunto de datos, este se carga como un bloque de variables y, por ello, si se hiciera la prueba de estacionariedad arrojaría como resultado la estacionariedad del bloque y no de la variable individualmente. Esta es la razón por la que hay que separarlas, crearlas. Las variables se extraerán de la base original (la que está en logaritmo natural) y no desde la que se convirtió en serie.
Creación de la variable FOB (Valor_FOB)
FOB <- Base$Valor_FOB; FOB <- ts(FOB)
## Start = 1 ; End = 121
## Frequency = 1
## [1] 11.1959885.541264 11.487892
## …
## [120] 10.819265 11.727073
Creación de la variable TaCam (Tasa_de_Cambio)
TaCam <- Base$Tasa_de_Cambio; TaCam <- ts(TaCam)
## Start = 1 ; End = 121
## Frequency = 1
## [1] 8.248050 8.203367 8.203367 8.203367 8.203367 8.248050 8.248050 8.203367
## …
## [121] 8.220040
Aplicación de las pruebas de raíz unitaria Dickey-Fuller (D - F) y Phillips-Perron (P - P), primero para la variable FOB:
adf.test(FOB); PP.test(FOB)
## Dickey-Fuller = -5.2934, Lag order = 4, p-value = 0.01
##Phillips-Perron Unit Root Test
## Dickey-Fuller = -10.513, Truncation lag parameter = 4, p-value = 0.01
Para interpretar estos p-value, se debió haber escogido el Alpha a trabajar previamente; en este caso se trabajará con 0,1. También se debe especificar la hipótesis nula, la cual, para estas pruebas, es:
Ho: La serie FOB tiene raíz unitaria.
El resultado es: p-valor de D - F: 0.01 < 0.1 p-valor de P - P: 0.01 < 0.1
Esto significa que a la variable FOB no se le debe aplicar una diferencia porque los p-value de ambas pruebas son menores a 0.1, o sea, ambos valores no tienen raíz unitaria. Acorde con Heivar Yesid Pinzón (2011), las series tienen sentido económico porque van en el mismo camino y los p-value son coherentes. El modelo VAR obliga a que se manejen igual número de diferencias o integraciones, para la variable FOB no se necesitó diferenciar; se debe probar la variable TaCam.
adf.test(TaCam); PP.test(TaCam)
## Dickey-Fuller = -4.0655, Lag order = 4, p-value = 0.01
##Phillips-Perron Unit Root Test
## Dickey-Fuller = -7.5405, Truncation lag parameter = 4, p-value = 0.01
Al igual que el procedimiento con la variable FOB Alpha = 0,1, también se debe especificar la hipótesis nula, la cual, para estas pruebas es:
Ho: La serie TaCam tiene raíz unitaria.
Los resultados son: p-valor de D - F: 0.01 < 0.1 p-valor de P - P: 0.01 < 0.1. Por esto, a la variable TaCam no se le debe aplicar una diferencia porque los p-value de ambas pruebas son menores a 0.1, o sea, ambos valores no tienen raíz unitaria. Como no se necesita crear una nueva base diferenciada, el grado de integración de las variables FOB y TaCam es I(0).
El paso siguiente es realizar las pruebas de causalidad de Granger. Se sigue utilizando la “serie” creada de “ts(Base)” porque no hubo diferenciaciones. Esta prueba es la realización de dos pruebas de hipótesis que justificarán la realización del modelo VAR, dado que ellas justifican la relación de corto plazo que podrían tener o no las variables “Tasa_de_Cambio” y “Valor_FOB” de los equipos celulares importados al Territorio Aduanero Nacional (TAN). Las pruebas de hipótesis para esta prueba de causalidad de Granger, con el paquete “vars” de R (Cran.r-project, 2022), son:
Ho: TaCam NO es causal de FOB.
Ho: FOB NO es causal de TaCam.
El Objetivo es: rechazar las DOS pruebas.
En la prueba de Granger aparecerá “order” = cuántos rezagos se requieren para rechazar Ho. Entre más alto el “order” mayor potencia tiene la prueba. “Order” varía desde 1 hasta el total de los datos (se corre uno por uno hasta que se logre rechazar), entonces, para la primera hipótesis:
grangertest(TaCam ~ FOB, order = 39, data = serie)
## Model 1: TaCam ~ Lags(TaCam, 1:39) + Lags(FOB, 1:39)
## Model 2: TaCam ~ Lags(TaCam, 1:39)
## Res.DfDfF Pr(>F)
## 13
## 2 42 -39 1.31950.4754
Ho: TaCam NO es causal de FOB, porque, p-value en order = 39 está dado por Pr(>F), y como 0.4754 > 0.1, NO se rechaza Ho., se corrió desde order 1 hasta 39. No hay relación de corto plazo.
Para la segunda hipótesis:
grangertest(FOB ~ TaCam, order = 39, data = serie)
## Model 1: FOB ~ Lags(FOB, 1:39) + Lags(TaCam, 1:39)
## Model 2: FOB ~ Lags(FOB, 1:39)
## 13
## 242 -39 0.7643 0.7146
Ho: FOB NO es causal de TaCam, porque, p-value en order = 39 está dado por Pr(>F), y como 0.7146 > 0.1, NO se rechaza Ho., no existe una relación de corto plazo.
Creación del modelo VAR(p), el orden p estará entre los rezagos del 1 al 6, esto se debe a que el modelo VAR es de corto plazo, se varía el orden p y se escoge el menor AIC.
VARselect(serie, lag.max = 6, type = "const")
## AIC(n)HQ(n)SC(n) FPE(n)
##1111
## 123 4 5 6
## AIC(n) -6.605704249 …
## HQ(n)-6.547574461 …
## SC(n)-6.462490399…
## FPE(n)0.001352662…
Se generan criterios de selección para seis modelos VAR. Se debe escoger solo un criterio de selección y con ese criterio se busca el menor valor. La prueba Granger no logró ser rechazada. Se escoge entre el AIC (AKAIKE) y el sc (BIC = Bayesian Information Criterium). Por AIC(n) el mejor modelo es un VAR(1), y por SC el mejor modelo es VAR(1). En este caso coinciden los dos. Se crea el modelo 1:
modelo1 <- VAR(serie, p = 1, type = "const")
## Endogenous variables: Tasa_de_Cambio, Valor_FOB
## Deterministic variables: const
## Sample size: 120
## Log Likelihood: 59.489
## Roots of the characteristic polynomial:
## 0.3623 0.03944
## Call:
## VAR(y = serie, p = 1, type = "const")
## Estimation results for equation Tasa_de_Cambio:
## =========================================
## Tasa_de_Cambio = Tasa_de_Cambio.l1 + Valor_FOB.l1 + const
##
## Estimate Std. Error t value Pr(>|t|)
## Tasa_de_Cambio.l1 0.37491130.0852769 4.396 2.44e-05 ***
## Valor_FOB.l10.00060220.0008497 0.709 0.48
## const 5.13555980.7020249 7.315 3.48e-11 ***
## ---
## Signif. codes:0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.01834 on 117 degrees of freedom
## Multiple R-Squared: 0.1432,Adjusted R-squared: 0.1286
## F-statistic: 9.779 on 2 and 117 DF,p-value: 0.0001183
## Estimation results for equation Valor_FOB:
## ==========================================
## Valor_FOB = Tasa_de_Cambio.l1 + Valor_FOB.l1 + const
##
## Estimate Std. Error t value Pr(>|t|)
## Tasa_de_Cambio.l1 -7.048669.27480-0.7600.449
## Valor_FOB.l1 0.026790.09241 0.2900.772
## const 68.15724 76.35295 0.8930.374
##
##
## Residual standard error: 1.995 on 117 degrees of freedom
## Multiple R-Squared: 0.005834,Adjusted R-squared: -0.01116
## F-statistic: 0.3433 on 2 and 117 DF,p-value: 0.7102
##
## Covariance matrix of residuals:
## Tasa_de_Cambio Valor_FOB
## Tasa_de_Cambio0.0003365 -0.001293
## Valor_FOB-0.00129303.980782
##
## Correlation matrix of residuals:
##Tasa_de_Cambio Valor_FOB
## Tasa_de_Cambio1.00000-0.03533
## Valor_FOB-0.03533 1.00000
Se continúa con la generación de la FIR (Función Impulso-Respuesta). Se debe “chocar” la variable TaCam (suponer un incremento del 1% en la variable TaCam), con lo cual, la FIR va a indicar si la variable FOB aumenta o disminuye (si el efecto es directo o inverso); además, indicará si el efecto en el tiempo se extingue o perdura.
modelo.fir1 <- irf(modelo1, impulse = "Tasa_de_Cambio", response = "Valor_FOB")
Impulse: se deja la variable que suponemos aumenta un 1% Response: Se deja la variable que recibe dicho efecto.
## Impulse response coefficients
## $Tasa_de_Cambio
## Valor_FOB
##[1,] -7.048201e-02
##…
## [11,] -1.548265e-05
## Lower Band, CI= 0.95
## $Tasa_de_Cambio
## Valor_FOB
##[1,] -0.3781475666
##…
## [11,] -0.0004992477
## Upper Band, CI= 0.95
## $Tasa_de_Cambio
##Valor_FOB
##[1,] 2.062182e-01
##…
## [11,] 2.149737e-05
FIGURA 8. Modelo.fir1: impulse = "Tasa_de_Cambio", response = "Valor_FOB".
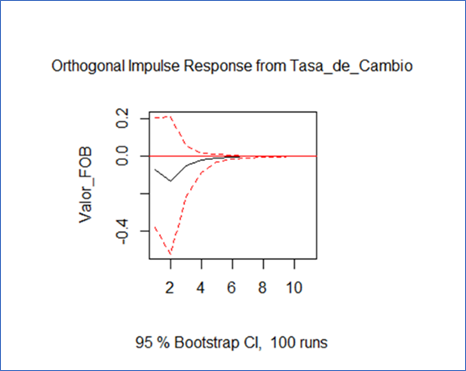
Fuente: Paquete “vars” de R a partir de (DIAN, 2022).
Se requiere que el gráfico muestre una mayor cantidad de picos por encima de cero para relación positiva o directa; o por debajo de cero para relación negativa o inversa. En la FIGURA 8 se evidencia una relación inversa de forma única. “Valor_FOB” empieza a disminuir en tres periodos, después de los cuales empieza a extinguirse el efecto generado en el tiempo. Quiere decir que por cada 1% que aumenta “Tasa_de_Cambio” baja “Valor_FOB”. Esta función Impulso – Respuesta explica la serie inicial, FIGURA 7, en donde se “apreciaban” comportamientos inversos.
Por rigurosidad académica se procede a cambiar el orden de las variables para impulsar “Valor_FOB”; como sigue siendo el mismo modelo, no se cambia “modelo.fir1”.
modelo.fir1 <- irf(modelo1, impulse = "Valor_FOB", response = "Tasa_de_Cambio")
modelo.fir1
## $Valor_FOB
## Tasa_de_Cambio
##[1,] 0.000000e+00
…
## [11,] 1.447659e-07
## Lower Band, CI= 0.95
## $Valor_FOB
## Tasa_de_Cambio
##[1,] 0.000000e+00
…
## [11,]-1.270776e-06
## Upper Band, CI= 0.95
## $Valor_FOB
## Tasa_de_Cambio
##[1,] 0.000000e+00
…
## [11,] 2.449155e-06
FIGURA 9. Modelo.fir1: impulse = "Valor_FOB", response =."Tasa_de_Cambio".
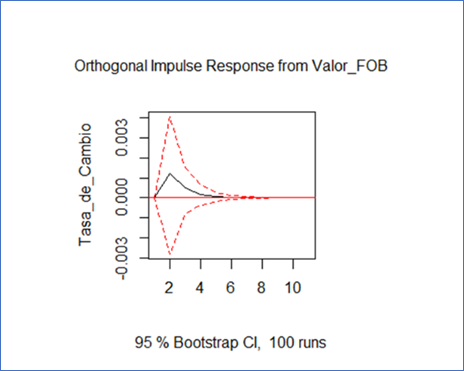
Fuente: Paquete “vars” de R a partir de (DIAN, 2022).
La FIGURA 9 tiene una relación directa. Si aumenta “Tasa_de_Cambio” en 1%, “Valor_FOB” aumenta y disminuye en tres periodos, después de los cuales, empieza a extinguirse el efecto generado en el tiempo. La validación del modelo se inicia probando la condición de estabilidad, en donde todas las raíces del polinomio deben estar por debajo de la unidad. Las raíces se calculan con:
roots(modelo1)
## [1] 0.36225886 0.03944165
En este caso no hay problema porque las raíces están por debajo de 1 ([1] 0.36225886 0.03944165). Si el valor fuera 1, el modelo queda descartado. Ahora, se debe realizar la prueba de autocorrelación de los residuales. Esto se hace con la prueba de Portmanteau y con la prueba de Breusch - Godfrey. La hipótesis para esta prueba es:
Ho: Los residuales son independientes.
Objetivo: NO rechazar Ho
serial.test(modelo1, lags.pt = 6) # pt para Portmanteau
p-value = 0.299
serial.test(modelo1, lags.bg = 6)
p-value = 0.5136
Dado que uno de los dos p-valores (en este caso los dos) son > 0.1, no se rechaza Ho, entonces se cumple la condición de independencia de los residuales.
Ahora, para la normalidad multivariada:
Ho: Los residuales siguen una distribución normal multivariada.
Objetivo: Si se rechaza no hay problema, dado que Fernández-Corugedo justificaron que es más importante la prueba de independencia que la normalidad en los modelos vectoriales. Si se acepta, el modelo es un poco más robusto.
normality.test(modelo1, multivariate.only = F)
## $Tasa_de_Cambio
##JB-Test (univariate)
## data:Residual of Tasa_de_Cambio equation
## Chi-squared = 8.0511, df = 2, p-value = 0.01785
##
## $Valor_FOB
##JB-Test (univariate)
## data:Residual of Valor_FOB equation
## Chi-squared = 26.173, df = 2, p-value = 2.073e-06
##
##Skewness only (multivariate)
## data:Residuals of VAR object modelo1
## Chi-squared = 34.489, df = 2, p-value = 3.243e-08
Como p-value JB-test 0.01785 < 0.1 se rechaza Ho.
Por último, con la función predictiva, que evidencia relación, se tiene:
pred <- predict(modelo1, n.ahead = 7, ci = 0.95)
pred
## $Tasa_de_Cambio
##fcstlowerupper CI
## [1,] 8.224407 8.188452 8.260362 0.03595497
…
## [7,] 8.225799 8.186991 8.264608 0.03880822
##
## $Valor_FOB
##fcstlowerupper CI
## [1,] 10.53115 6.620650 14.44165 3.910500
…
## [7,] 10.45655 6.534670 14.37844 3.921885
FIGURA 10. Predicción variables Tasa_de_Cambio” y “Valor_FOB”.
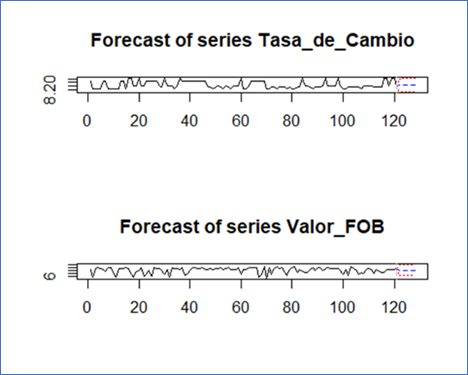
Fuente: Paquete “vars” de R a partir de (DIAN, 2022)
La FIGURA 10, de acuerdo con los datos históricos, predice que no cambiará el patrón de no incrementarse el valor FOB y se mantendrá una tasa de cambio en un intervalo de confianza entre 8.264608 y 8.3880822.
Analítica Descriptiva
El valor FOB no presenta una tendencia hacia arriba. Indicaría esto que los precios mundiales (valor FOB) no subieron para los celulares en los seis años estudiados. Esta situación es atípica, pues el precio final al consumidor en Colombia, en el mismo periodo de tiempo, sí ha tenido incrementos por parte de las empresas comercializadoras de estos equipos. Se presentan las FIGURAS 11 y 12 con los consolidados totales de los valores FOB de las importaciones realizadas en Colombia en cada uno de los años. En la FIGURA 11 se tienen en cuenta todos los años objeto de estudio, 2015 a 2020. En la FIGURA 12 solo se tienen en cuenta los años 2017 al 2020. La razón de esto es la entrada en vigencia de la Ley 1819 de 2016, expedida el 29 de diciembre de ese año (Secretaría del Senado, 2016b). Ambas figuras tienen dos líneas de tendencia que representan la suma del Valor FOB unitario por año de esa subpartida arancelaria.
La línea inferior es el total del valor FOB unitario declarado al momento de presentar la declaración de importación en cualquiera de sus tipos (anticipada, inicial, corrección, legalización o modificación). La línea superior representa el valor límite consolidado que deberían pagar los importadores, de acuerdo con la Ley 1819. Se tienen en cuenta los años 2015 y 2016 para efectos de verificar tendencia, pues estos años no hacen parte de la Ley 1819. En la FIGURA 11 se muestra que, para la importación de teléfonos móviles celulares en los años 2015 y 2016, se establecieron como tributos aduaneros un gravamen arancelario de cero por ciento (0%) y una tarifa del IVA del 16%. En la gráfica se observa la tendencia a declarar un valor FOB por unidad bajo, con el fin de reducir la base impositiva y lograr una liquidación menor en el pago de los tributos. Los valores FOB declarados en el consolidado no sobrepasan nunca los límites legales, 22 UVT (Unidades de Valor Tributario), están “anclados” a valores inferiores al permitido por la ley. El valor FOB no declarado fue de USD 6.116.885; si se hubieran declarado el fisco nacional tendría base para cobro de impuestos (línea verde). Estos son valores nominales que en otro estudio podrían ser determinados con precios de venta FOB “ajustados a realidad”.
FIGURA 11. Caracterización y tendencia del valor FOB de celulares referidos al Artículo 175 de la Ley 1819/2016, incluidos los años 2015 y 2016.
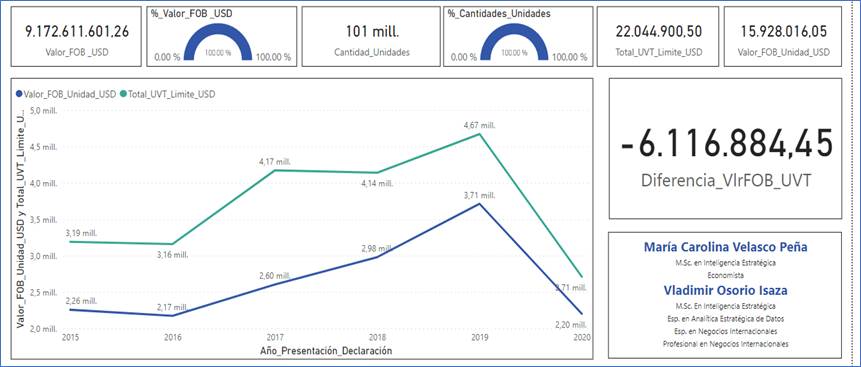
Fuente: Elaboración propia a partir de (DIAN, 2022) utilizando Power BI.
A partir del año 2017, cuando se condicionó la exclusión del pago del IVA en los casos cuyo valor no excediera de veintidós (22) UVT, se observa que la tendencia es mantener un valor FOB por unidad bajo el límite del cálculo de las UVT en dólares, lo cual implica la importación de teléfonos móviles inteligentes sin el pago de tributos aduaneros. En este caso, sin los años 2015 y 2016, para lograr base de tributación se necesitarían USD 4.196.930.
FIGURA 12. Caracterización y tendencia de los precios de celulares referidos al Artículo 175 de la Ley 1819/2016, exclusivamente en los años de su aplicación.
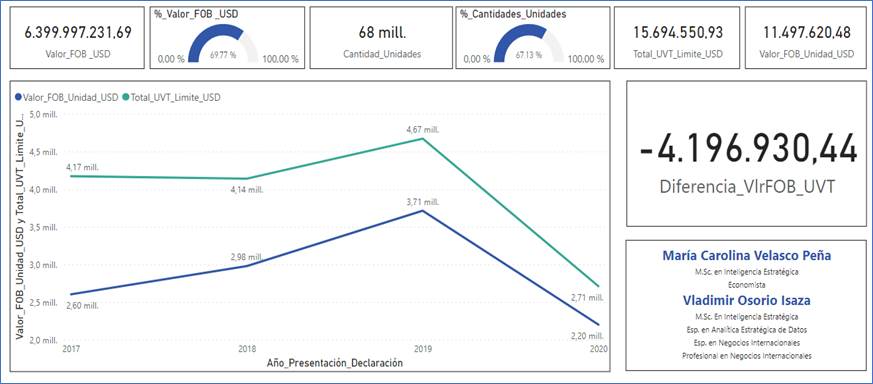
Fuente: Elaboración propia a partir de (DIAN, 2022) utilizando Power BI.
Pasando a la gestión en aduanas, FIGURAS 13 y 14, desde el control simultáneo a través del sistema informático aduanero se determina la inspección aduanera de la mercancía. En la FIGURA 13 se muestra que del total de declaraciones de importación presentadas (95.985) un 73.67% obtienen levante automático, y en la inspección física o documental a solo un 17.92% se le realiza controversia de valor para ajuste. Por países, el principal país de origen de los celulares es China, con un 85.72%, seguido de Vietnam, con 9.97%. Esto es relevante teniendo en cuenta que son países con perfilamiento alto y es baja la controversia de valor a pesar de tener un elemento atípico como es que, el valor FOB no tiene tendencia a subir en los seis años objeto de estudio. Por país de compra sobresale Estados Unidos, con 32.65% y Corea del Sur, con 20.92%, que son los países en los que los importadores “negocian” los productos. Estos países cambian al momento de realizar la operación de distribución física internacional (DFI), ejemplo de ello son los países de procedencia, donde se destaca Hong Kong, con 41.94%, seguido de China con 26.65%.
FIGURA 13. Dashboard del total de declaraciones presentadas por selectividad, unidades y valor FOB.
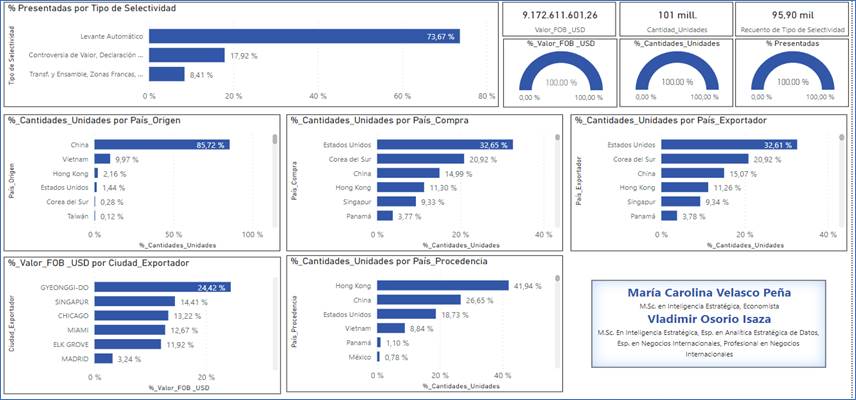
Fuente: Elaboración propia a partir de (DIAN, 2022) utilizando Power BI.
Power BI permite flexibilidad en los análisis al relacionar atributos y vectores de una base de datos, este es el caso de la FIGURA 14 en donde se selecciona a China en el cuadro que relaciona “%_Cantidades_Unidades por País_Origen”. El resultado es que a las mercancías que son de este origen solo se les realizó un 16,05% de controversias de valor, un importador sabría que tiene un 60% de posibilidades de tener levante automático. Estas importaciones con este origen representaron el 84,25% del total del valor FOB declarado y del 85,72% de todas las unidades que ingresaron al TAN colombiano.
FIGURA 14. Dashboard de las declaraciones presentadas del origen “China” categorizadas por selectividad, unidades y valor FOB.
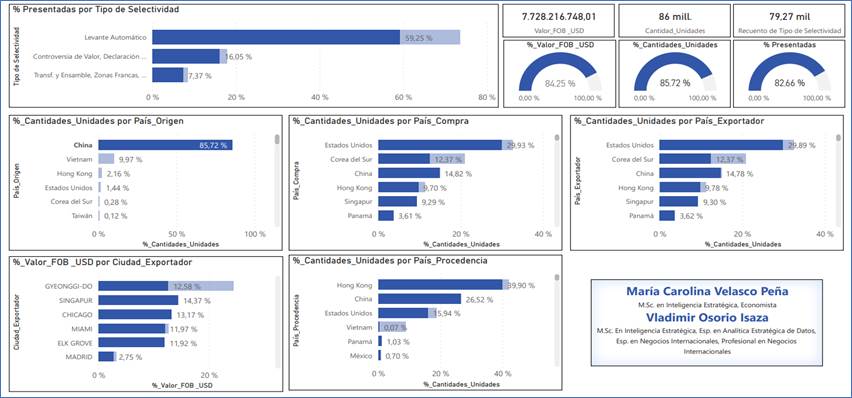
Fuente: Elaboración propia a partir de (DIAN, 2022) utilizando Power BI.
Revisando probabilidad con la misma herramienta de inteligencia de negocios, se tiene que, a través de la media, la mayor probabilidad de que el valor FOB por unidad aumente es cuando el país exportador sea Suecia (FIGURA 15), lo que perfila a este país con menor riesgo de subvaloración en el valor FOB de los equipos.
FIGURA 15. Dashboard con la probabilidad de aumento del valor FOB de acuerdo con el país exportador.
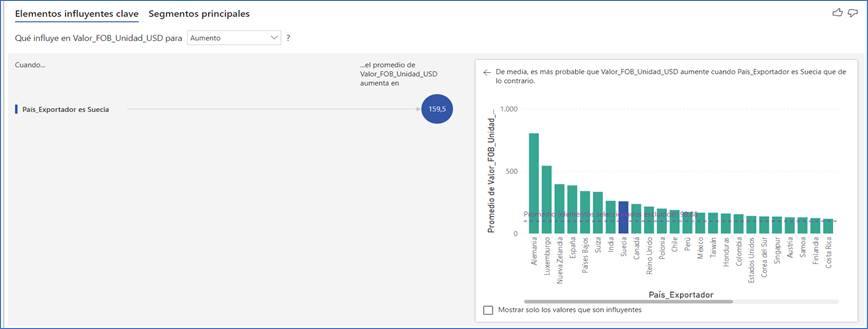
Fuente: Elaboración propia a partir de (DIAN, 2022) utilizando Power BI.
De manera contraria, en la FIGURA 16 la mayor probabilidad de que el valor FOB por unidad disminuya (haya subvaloración) es cuando el país exportador es China (93.53), seguido de Hong Kong (87.09) y Bulgaria (84.04). Cuando se simula el “País_Origen” la mayor probabilidad de subvaloración es de Hong Kong, país desde donde más cantidades proceden (FIGURA 14).
FIGURA 16. Dashboard con la probabilidad de subvaloración del valor FOB de acuerdo con el país exportador.
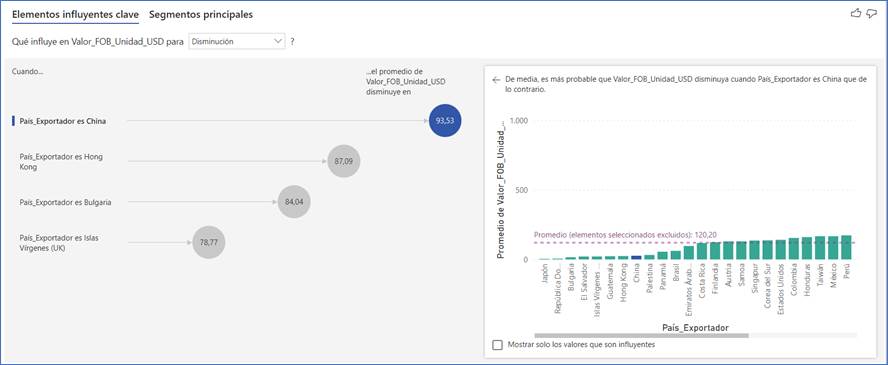
Fuente: Elaboración propia a partir de (DIAN, 2022) utilizando Power BI.
Utilizando los objetos visuales de Inteligencia Artificial de Power BI, se tiene que el mayor porcentaje de levantes automáticos se da por la Dirección Seccional de Aduanas de Bogotá, cuando el país de origen es China, y el país de compra y de procedencia es Estados Unidos, específicamente desde la ciudad de Miami (FIGURA 17). Esta información es de utilidad para los decisores aduaneros al momento de perfilar orígenes y destinos. Esta es una descripción enfocada en el más representativo, pero con la herramienta el abanico de posibilidades de análisis es muy amplio. En las FIGURAS 17 y 18 se pueden observar diferentes rutas de acuerdo con el tipo de selectividad (levante automático, declaración de corrección por controversia de valor y declaraciones con ajuste negativo por transformación o elaboración (zonas francas)).
FIGURA 17. Dashboard jerárquico de los objetos visuales de Inteligencia artificial de las declaraciones presentadas bajo el criterio de selectividad “levante automático”.
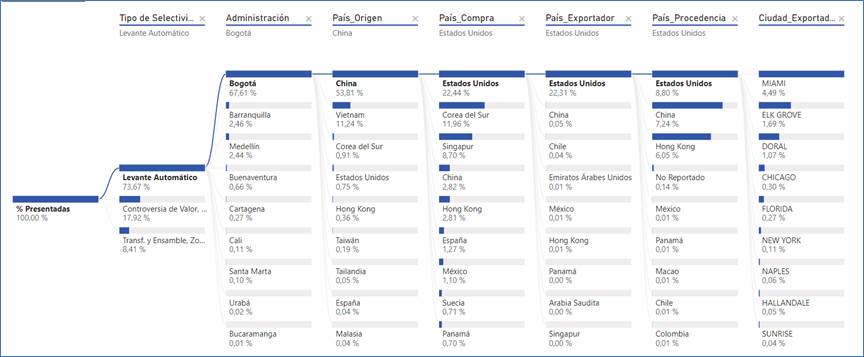
Fuente: Elaboración propia a partir de (DIAN, 2022) utilizando Power BI.
Por ejemplo, en el control simultáneo, las controversias de valor para ajuste se realizaron mayormente en la Dirección Seccional de Aduanas de Bogotá, seguida de las DSA de Barranquilla, Buenaventura y Cartagena, cuando el país de origen es China, y el país de compra y de procedencia es Estados Unidos.
FIGURA 18. Dashboard jerárquico de los objetos visuales de Inteligencia artificial de las declaraciones presentadas bajo el criterio de selectividad “Controversia de valor”.
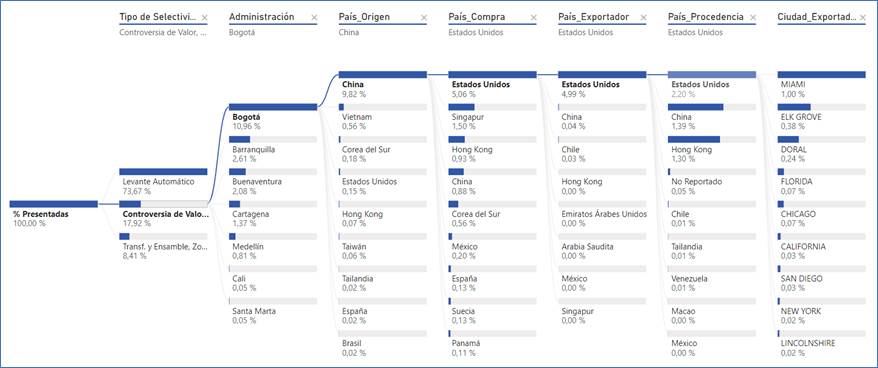
Fuente: Elaboración propia a partir de (DIAN, 2022) utilizando Power BI.
Ahora, si se evalúa la selectividad en las Direcciones Seccionales de Impuestos y Aduanas (DSIA) de Armenia, Bucaramanga y Urabá son por las cuales el 100% de las declaraciones presentadas obtienen levante automático, teniendo en cuenta que la importación de teléfonos celulares por estas seccionales es muy baja. Se muestra cómo la DSA de Bogotá es la principal aduana de ingreso de estas importaciones, mostrando un 81.30% de levantes automáticos. Por otra parte, la DSA de Cartagena es donde se realiza la mayor cantidad de controversias para ajuste de valor en un 57.28%, seguida de la DSIA Buenaventura con 52.63%. Además, en la DSIA de Valledupar se observa la presentación de declaración con ajuste negativo. Esta información puede ser valorada por decisores aduaneros y por personas dedicadas al comercio internacional y comercio exterior al momento del diseño de la distribución física internacional de los teléfonos celulares.
FIGURA 19. Selectividad en las Direcciones Seccionales de Impuestos y Aduanas (DSIA).
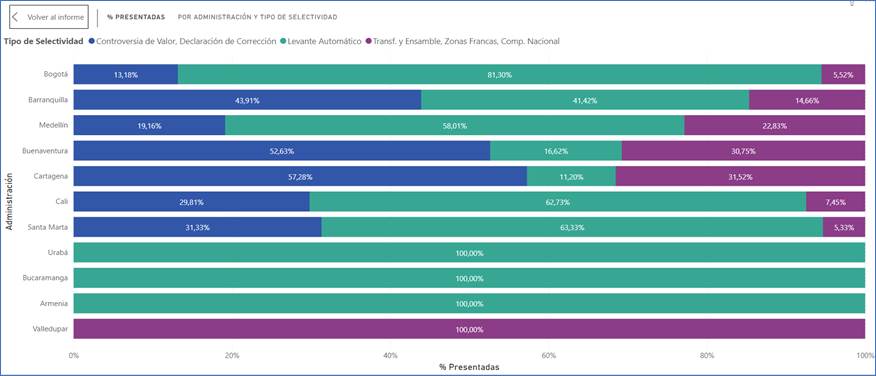
Fuente: Elaboración propia a partir de (DIAN, 2022) utilizando Power BI.
El análisis por tipo de declaración a nivel nacional muestra que las declaraciones iniciales son las más presentadas en la importación de teléfonos móviles celulares, seguida de las declaraciones tipo corrección, debido en su mayoría a los ajustes realizados por controversias de valor. Por otra parte, las declaraciones de legalización muestran una baja proporción, a excepción de las presentadas en la DSIA de Valledupar con un 100%. Finalmente, las declaraciones tipo anticipadas y de modificación registran un bajo porcentaje de presentación para el producto de estudio.
FIGURA 20. Tipo de declaración presentada por administración.
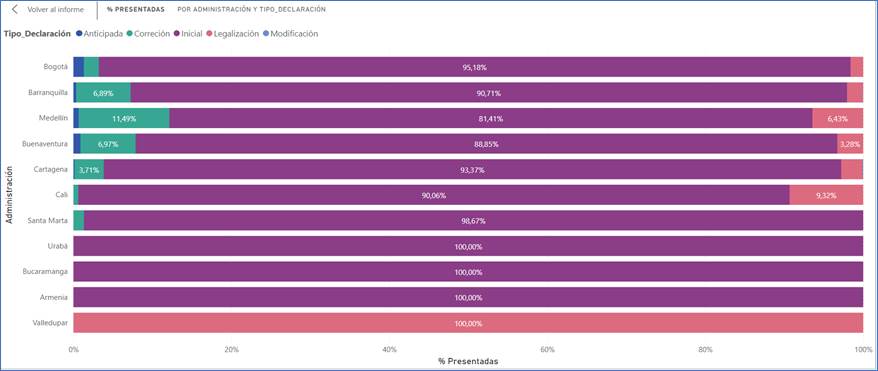
Fuente: Elaboración propia a partir de (DIAN, 2022) utilizando Power BI.
Conclusiones
Los precios unitarios de los celulares declarados en Colombia al momento de realizar el proceso de importación no varían por valores concernientes a costos de producción o estrategias de ventas de las casas matrices, sino acorde con la TRM o a la tasa de cambio conforme convenga. No necesariamente es un delito, pues la ley permite importar teléfonos celulares de acuerdo con franjas establecidas en UVT. La autoridad aduanera debería considerar este tipo de estudios analíticos donde se detectan patrones para tomar decisiones respecto de la gestión aduanera y proteger el fisco nacional.
Conforme con la aplicación del primer método "Valor de Transacción de las mercancías importadas", establecido en el Acuerdo sobre Valoración de la Organización Mundial del Comercio, la factura comercial como documento soporte es determinante para establecer el precio realmente pagado o por pagar. Sin embargo, cuando dentro de las labores del control simultáneo se advierte la presunta falsedad o alteración de los datos consignados en la factura, el procedimiento para determinar y probar este hecho es dispendioso y puede requerir de tiempo.
Se debe dar mayor importancia a la rigurosidad en la verificación del valor facturado y lo que físicamente se está nacionalizando, lo que se encuentra en zona primaria aduanera. Esto debe ocurrir durante el control simultáneo, la determinación de la inspección aduanera (física o documental), o autorización de levante automático a través del sistema informático aduanero. Es ahí, de acuerdo con la evidencia, donde se debe enfocar el esfuerzo de tener en cuenta las descripciones particulares de los equipos (teléfonos), que en últimas se convierte en la información fundamental para determinar su valoración.
De acuerdo con las evidencias, los mecanismos administrativos implementados en Colombia para prevenir la subvaloración en la importación de teléfonos móviles (celulares) no son suficientemente eficaces para controlar y prevenir este fenómeno, en detrimento de los ingresos estatales.
Referencias
Banco de la República. (s. f.). Tasa Representativa del Mercado (TRM - Peso por dólar) | Banco de la República. Recuperado 29 de septiembre de 2022, de https://www.banrep.gov.co/es/estadisticas/trm
BLU Radio, R. B. (2020, noviembre 19). Policía incauta 40 iPhone 12 de contrabando en el aeropuerto Eldorado (world) [Text]. Blu Radio; Blu Radio. https://www.bluradio.com/judicial/policia-incauta-40-iphone-12-de-contrabando-en-el-aeropuerto-el-dorado
Castro, C. A. A., Reina, J.
J., Moncada, A. M., Benítez, E. P. R., Guzmán, H. M. A., López, J. V. S.,
Valderrama, M. N. H., Cortés, R. A., Hurtado, C., Franco, H. C., Sabogal, B. J.
R., Plata, A. P., Sanabria, Ó. O. C., Carreño, L. G., & Hidalgo, P. I. M.
(2020). Aportes teóricos a
la construcción del concepto de inteligencia estratégica. En Sello Editorial
ESDEG. Sello Editorial ESDEG. https://doi.org/10.25062/9789584288974
PMid:32904213
Cran.r-project. (2022). The Comprehensive R Archive Network. https://cran.r-project.org/
DIAN. (2022). Estadísticas. Estadísticas DIAN. https://www.dian.gov.co/dian/cifras/Paginas/estadisticas.aspx
DIAN, Ministerio de Hacienda y Crédito Público. (2022). Inicio Valoración de Mercancías / Preguntas Frecuentes. Preguntas Frecuentes. https://www.dian.gov.co/aduanas/aspectecmercancias/valoracion_de_mercancias/Preguntas_frecuentes/Paginas/default.aspx#collapse11
Dirección de Impuestos y Aduanas Nacionales—DIAN. (s. f.). Estadísticas. Recuperado 24 de septiembre de 2022, de https://www.dian.gov.co/
Estadística delictiva. (2017, marzo 18). Policía Nacional de Colombia. https://www.policia.gov.co/grupo-informacion-criminalidad/estadistica-delictiva
Joyanes Aguilar, L. (2017). Industria 4.0: La cuarta revolución industrial (1ra. Edición). Alfaomega.
Lind, D. A., Marchal, W. G., & Wathen, S. A. (2015). Estadística Aplicada a los negocios y la Economía (16ta. Edición). McGraw Hill / Interamericana Editores S.A. de C.V.
Meisel Lanner, R. (2020). La importancia del sistema de gestión del riesgo aduanero. Revista de Derecho, 53, 111-135. https://rcientificas.uninorte.edu.co/index.php/derecho/article/view/11954 https://doi.org/10.14482/dere.53.344.3
Osorio Isaza, V., Chaparro Betancourt, N., & Sandoval Perdomo, A. E. (2021). China, Estados Unidos y 5G: Capitalismo de Vigilancia, Geopolítica y Geoestrategia. Revista Perspectivas en Inteligencia, 12(21), 13. https://doi.org/10.47961/2145194X.218
Paravicini Guzmán, R. E. (2016). El fraude aduanero y su efecto en la renta aduanera en Bolivia. 15.
Pinzón, H. Y. R. (2011). Estudio del Fenómeno de Inflación Importada vía precios del Petróleo y su aplicación al caso colombiano mediante el uso de modelos Var para el periodo 2000-2009. Estudios Gerenciales, 27(121), 79-97. https://www.redalyc.org/articulo.oa?id=21222885004 https://doi.org/10.1016/S0123-5923(11)70182-6
Procolombia. (s. f.). Incoterms® 2020 | Portal de Exportaciones—Colombia Trade. Herramientas y servicios para el exportador. Recuperado 29 de septiembre de 2022, de https://www.colombiatrade.com.co/herramientas-del-exportador/logistica/incoterms-2020
Sampieri, R. H. (2018). METODOLOGÍA DE LA INVESTIGACIÓN: LAS RUTAS CUANTITATIVA, CUALITATIVA Y MIXTA. McGraw Hill México.
Secretaría del Senado. (2016a). DECRETO 1625 DE 2016. https://www.suin-juriscol.gov.co/viewDocument.asp?ruta=Decretos/30030361
Secretaría del Senado. (2016b). LEY 1819 DE 2016. https://www.suin-juriscol.gov.co/viewDocument.asp?ruta=Leyes/30030265
Secretaría del Senado. (2019). DECRETO 1165 DE 2019. https://www.suin-juriscol.gov.co/viewDocument.asp?id=30036618
Secretaría General de la Comunidad Andina. (2007). Lucha contra el Fraude. https://www.comunidadandina.org/StaticFiles/201165195437libro_atrc_fraude.pdf
Solano Medina, C., & Lombana Sierra, J. I. (2015). Comentarios sobre el nuevo delito de fraude aduanero. 36.
Subba Rao, S. (2022). A course in Time Series Analysis. 527. https://web.stat.tamu.edu/~suhasini/teaching673/time_series.pdf
Tiempo, C. E. E. (2015a). Caen las ventas de celulares en Colombia. Portafolio.co. https://www.portafolio.co/negocios/empresas/caen-ventas-celulares-colombia-35460
Tiempo, C. E. E. (2015b, septiembre 29). Celulares de menos de U$ 5 entran legales al país / Análisis. El Tiempo. https://www.eltiempo.com/archivo/documento/CMS-16389948
Time series analysis with applications in R (Second Edition). (2008). https://link.springer.com/book/10.1007/978-0-387-75959-3